Analysis-by-Synthesis Transformer for Single-View 3D Reconstruction
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
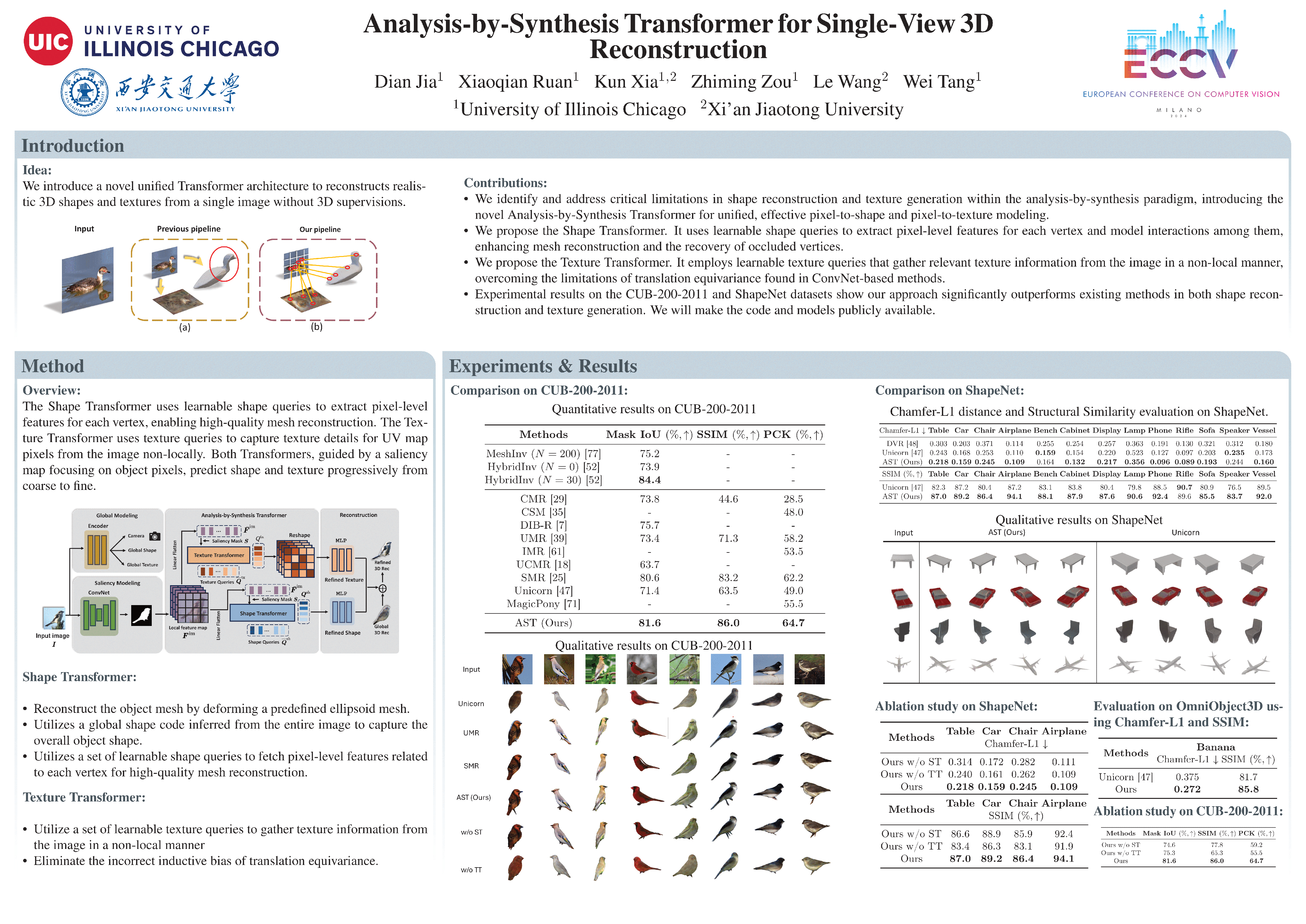
Deep learning approaches have made significant success in single-view 3D reconstruction, but they often rely on expensive 3D annotations for training. Recent efforts tackle this challenge by adopting an analysis-by-synthesis paradigm to learn 3D reconstruction with only 2D annotations. However, existing methods face limitations in both shape reconstruction and texture generation. This paper introduces an innovative Analysis-by-Synthesis Transformer that addresses these limitations in a unified framework by effectively modeling pixel-to-shape and pixel-to-texture relationships. It consists of a Shape Transformer and a Texture Transformer. The Shape Transformer employs learnable shape queries to fetch pixel-level features from the image, thereby achieving high-quality mesh reconstruction and recovering occluded vertices. The Texture Transformer employs texture queries for non-local gathering of texture information and thus eliminates incorrect inductive bias. Experimental results on CUB-200-2011 and ShapeNet datasets demonstrate superior performance in shape reconstruction and texture generation compared to previous methods. We will make code publicly available.