Deep Nets with Subsampling Layers Unwittingly Discard Useful Activations at Test-Time
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
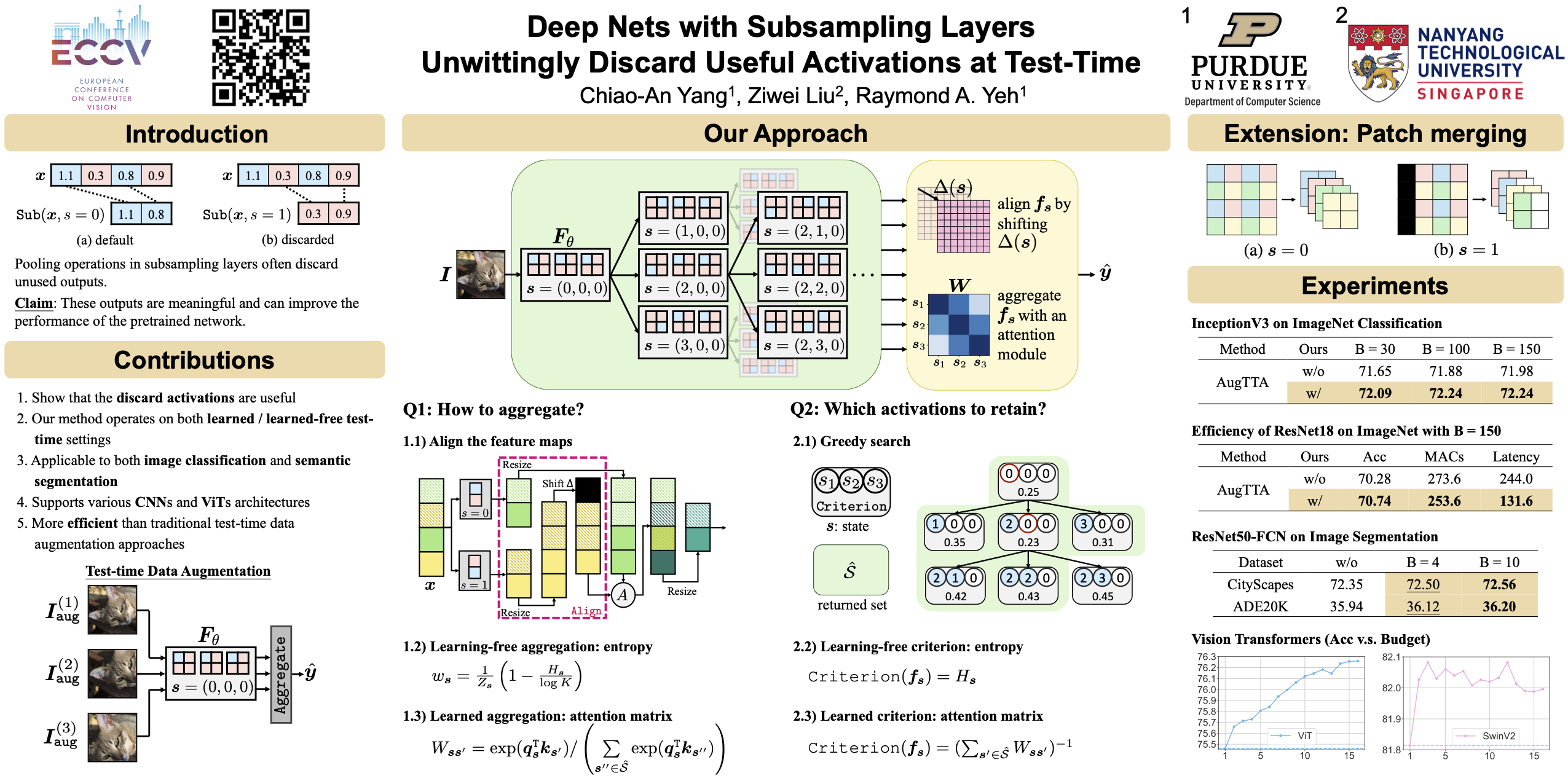
Subsampling layers play a crucial role in deep nets by discarding a portion of an activation map to reduce its spatial dimensions. This encourages the deep net to learn higher-level representations. Contrary to this motivation, we hypothesize that the discarded activations are useful and can be incorporated on the fly to improve models' prediction. To validate our hypothesis, we propose a search and aggregate method to find useful activation maps to be used at test-time. We applied our approach to the task of image classification and semantic segmentation. Extensive experiments over nine different architectures on ImageNet, CityScapes, and ADE20K show that our method consistently improves model test-time performance. Additionally, it complements existing test-time augmentation techniques to provide further performance gains.