Instruction Tuning-free Visual Token Complement for Multimodal LLMs
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
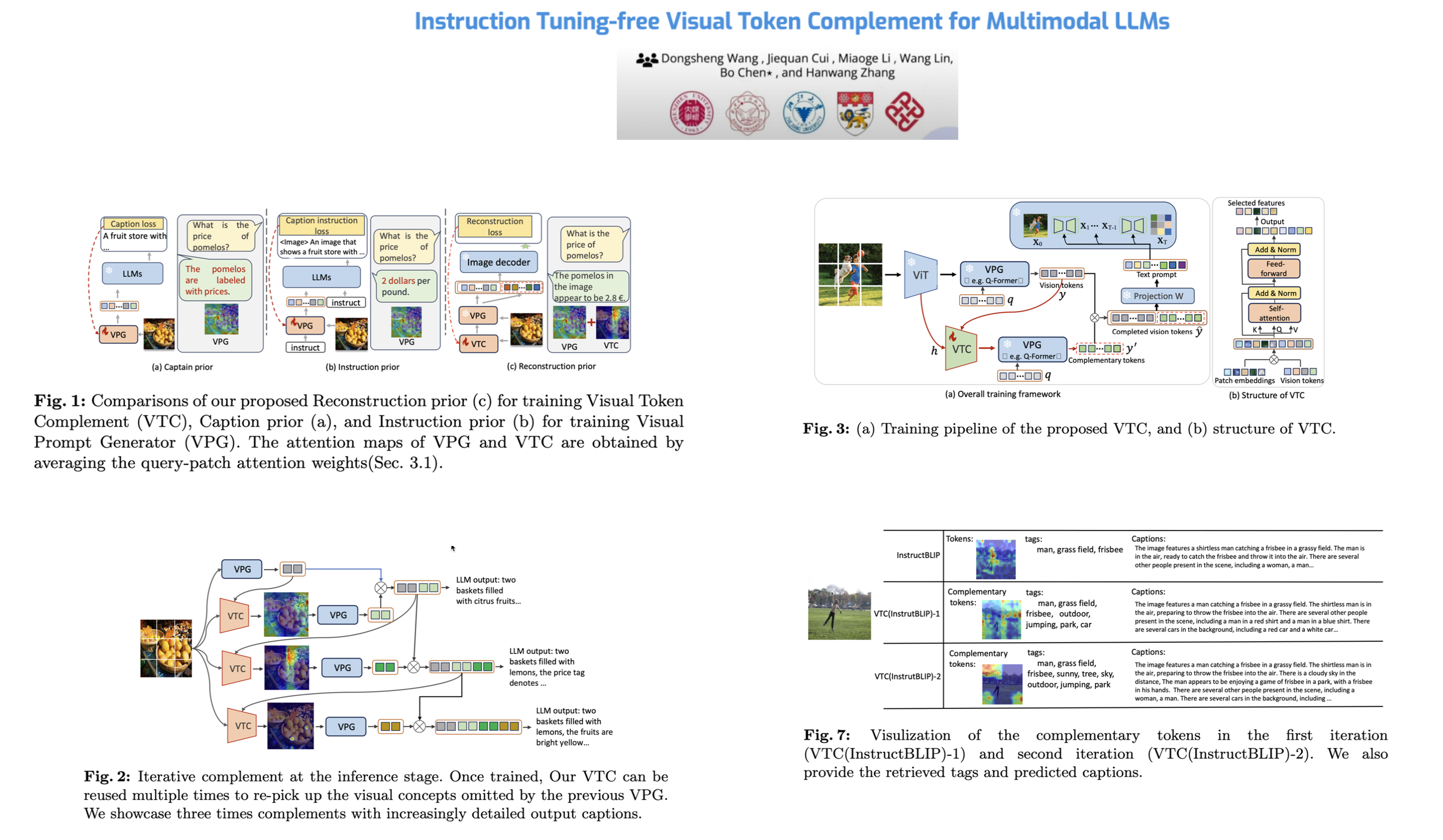
As the open community of large language models (LLMs) matures, multimodal LLMs (MLLMs) have promised an elegant bridge between vision and language. However, current research is inherently constrained by challenges such as the need for high-quality instruction pairs and the loss of visual information in image-to-text training objectives. To this end, we propose a Visual Token Complement framework (VTC), that helps MLLMs regain the missing visual features and thus improve response accuracy. Specifically, our VTC integrates text-to-image generation as a guide to identifying the text-irrelevant features, and a visual selector is then developed to generate complementary visual tokens to enrich the original visual input. Moreover, an iterative strategy is further designed to extract more visual information by iteratively using the visual selector without any additional training. Notably, the training pipeline requires no additional image-text pairs, resulting in a desired instruction tuning-free property. Both qualitative and quantitative experiments demonstrate the superiority and efficiency of our VTC. Codes are in the Appendix.