Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
{kind=link}
Abstract
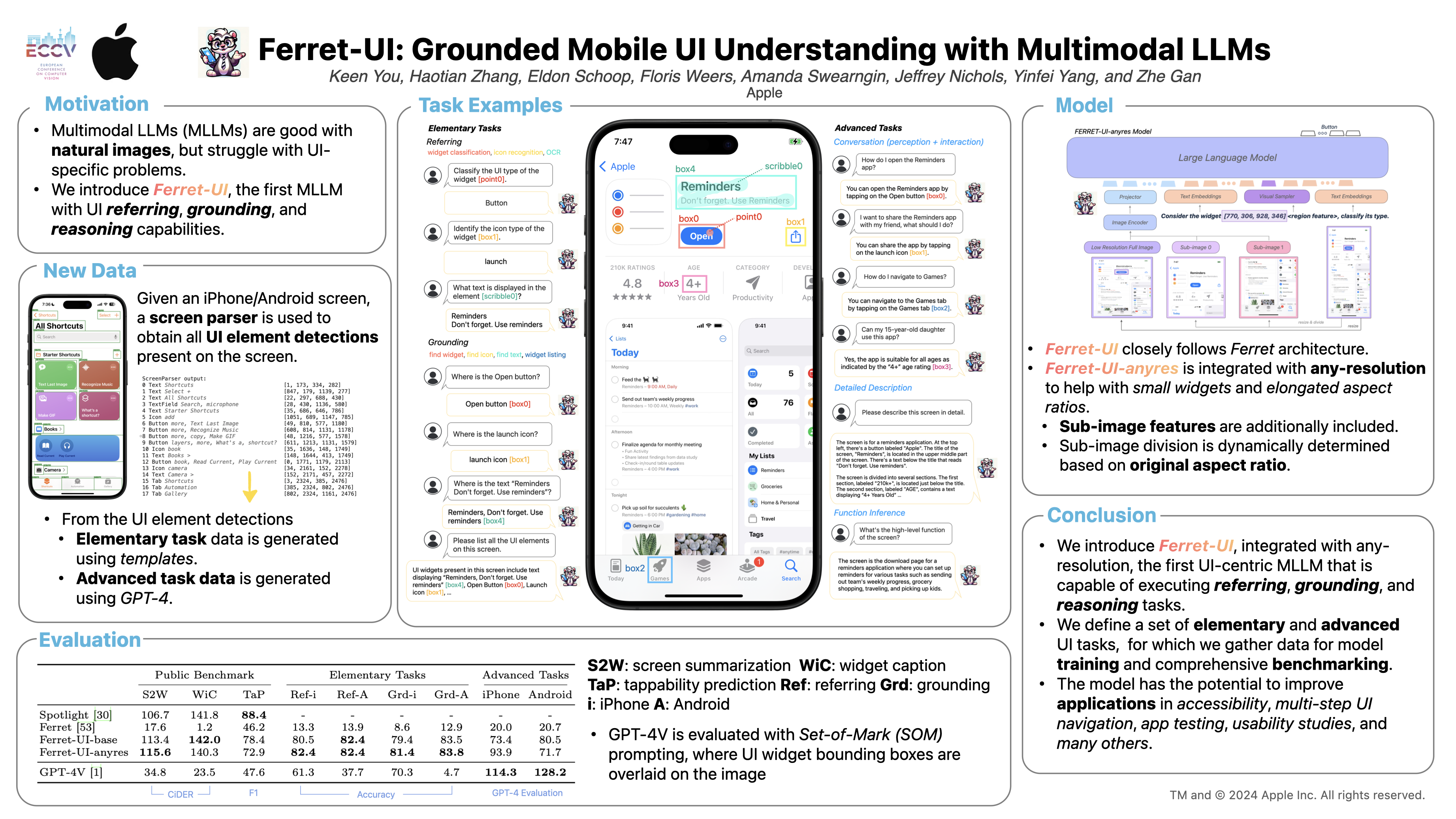
The recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we construct Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. we meticulously gathered training samples from an extensive range of fundamental UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. Moreover, to augment the model's reasoning ability, we compile a dataset for advanced tasks inspired by Ferret, but with a focus on mobile screens. This methodology enables the training of Ferret-UI, a model that exhibits outstanding comprehension of UI screens and the ability to execute open-ended instructions, thereby facilitating UI operations. To rigorously evaluate its capabilities, we establish a comprehensive benchmark encompassing the aforementioned tasks. Ferret-UI not only outstrips most open-source UI MLLMs in performance but also achieves parity with GPT-4V, marking a significant advancement in the field.