Semantically Guided Representation Learning For Action Anticipation
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
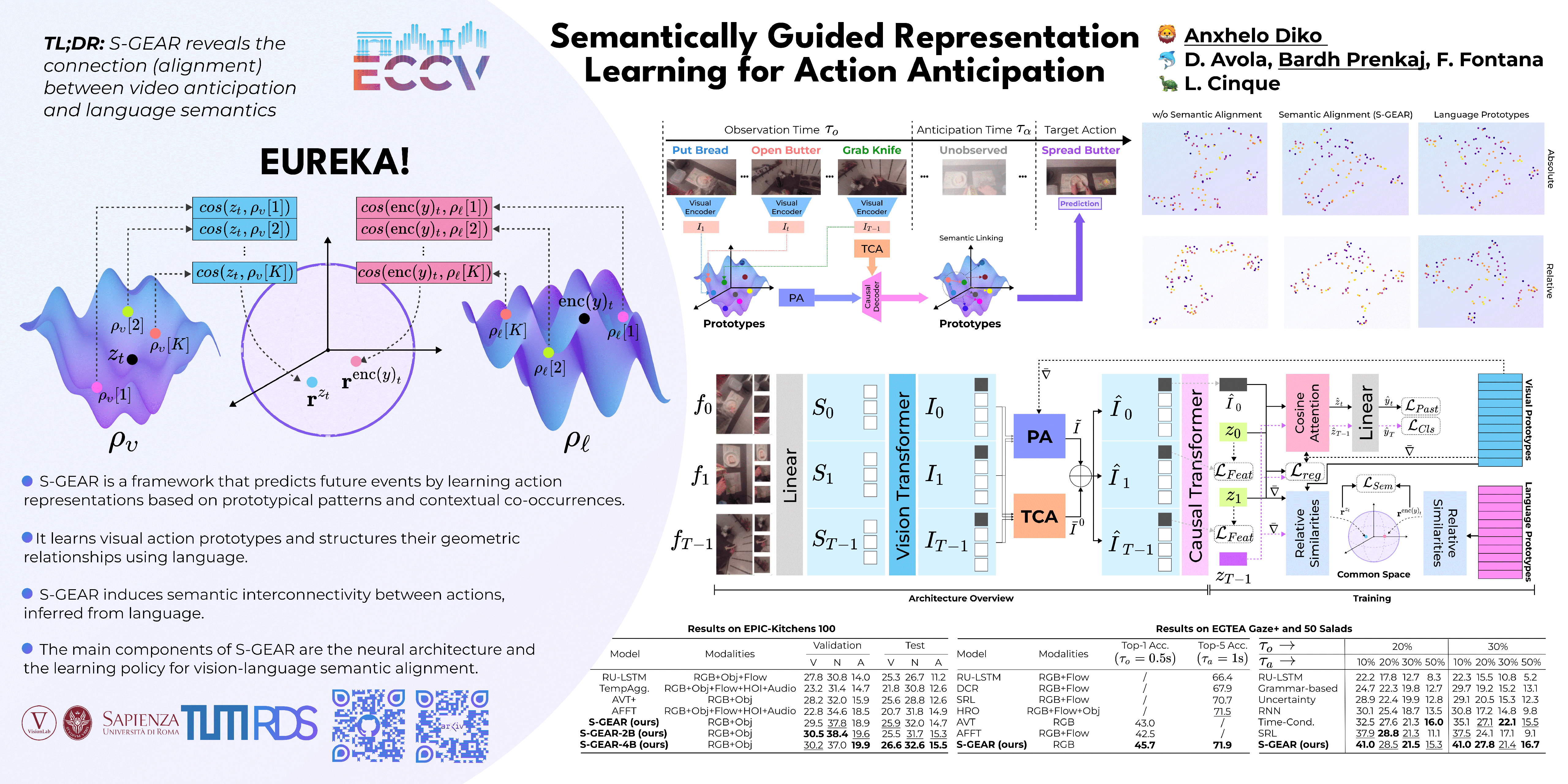
Action anticipation is the task of forecasting future activity from a partially observed sequence of events. However, this task is exposed to intrinsic future uncertainty and the difficulty of reasoning upon interconnected actions. Unlike previous works that focus on extrapolating better visual and temporal information, we concentrate on learning action representations that are aware of their semantic interconnectivity based on prototypical action patterns and contextual co-occurrences. To this end, we propose the novel Semantically Guided Representation Learning (S-GEAR) framework. S-GEAR learns visual action prototypes and leverages language models to structure their relationship, inducing semanticity. To gather insights on S-GEAR's effectiveness, we experiment on four action anticipation benchmarks, obtaining improved results compared to previous works: +3.5, +2.7, and +3.5 on Top-1 accuracy on Epic-Kitchen 55, EGTEA Gaze+ and 50 Salads, respectively, and +0.8 on Top-5 Recall on Epic-Kitchens 100. We further observe that S-GEAR effectively transfers the geometric associations between actions from language to visual prototypes. Finally, by exploring the intricate impact of action semantic interconnectivity, S-GEAR opens new research frontiers in anticipation tasks.