EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
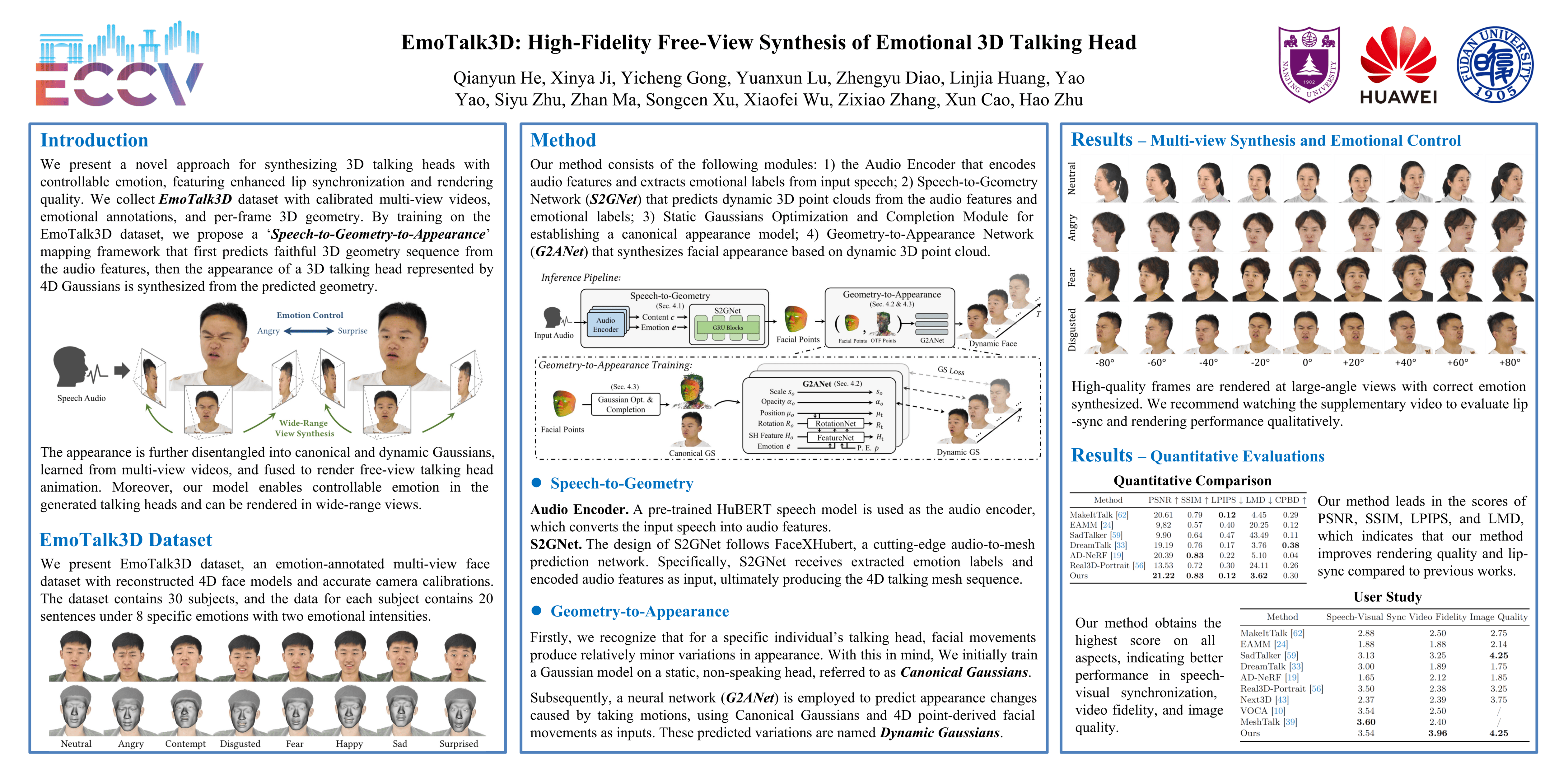
We present a novel approach for synthesizing emotion-controllable 3D talking heads, featuring enhanced lip synchronization and rendering quality. Despite significant progress in the field, prior methods still suffer from multi-view consistency and a lack of emotional expressiveness. To address these issues, we collect EmoTalk3D dataset with calibrated multi-view videos, emotional annotations, and per-frame 3D geometry. By training on the EmoTalk3D dataset, we propose a 'Speech-to-Geometry-to-Appearance' mapping framework that first predicts faithful 3D geometry sequence from the audio features, then the appearance of a 3D talking head represented by 4D Gaussians is synthesized from the predicted geometry. The appearance is further disentangled into canonical and dynamic Gaussians, learned from multi-view videos, and fused to render free-view talking head animation. Moreover, our model extracts emotion labels from the input speech and enables controllable emotion in the generated talking heads. Our method exhibits improved rendering quality and stability in lip motion generation while capturing dynamic facial details such as wrinkles and subtle expressions. Experiments demonstrate the effectiveness of our approach in generating high-fidelity and emotion-controllable 3D talking heads. The code and EmoTalk3D dataset will be publicly released upon publication.