Distill Gold from Massive Ores: Bi-level Data Pruning towards Efficient Dataset Distillation
{kind=link}
Abstract
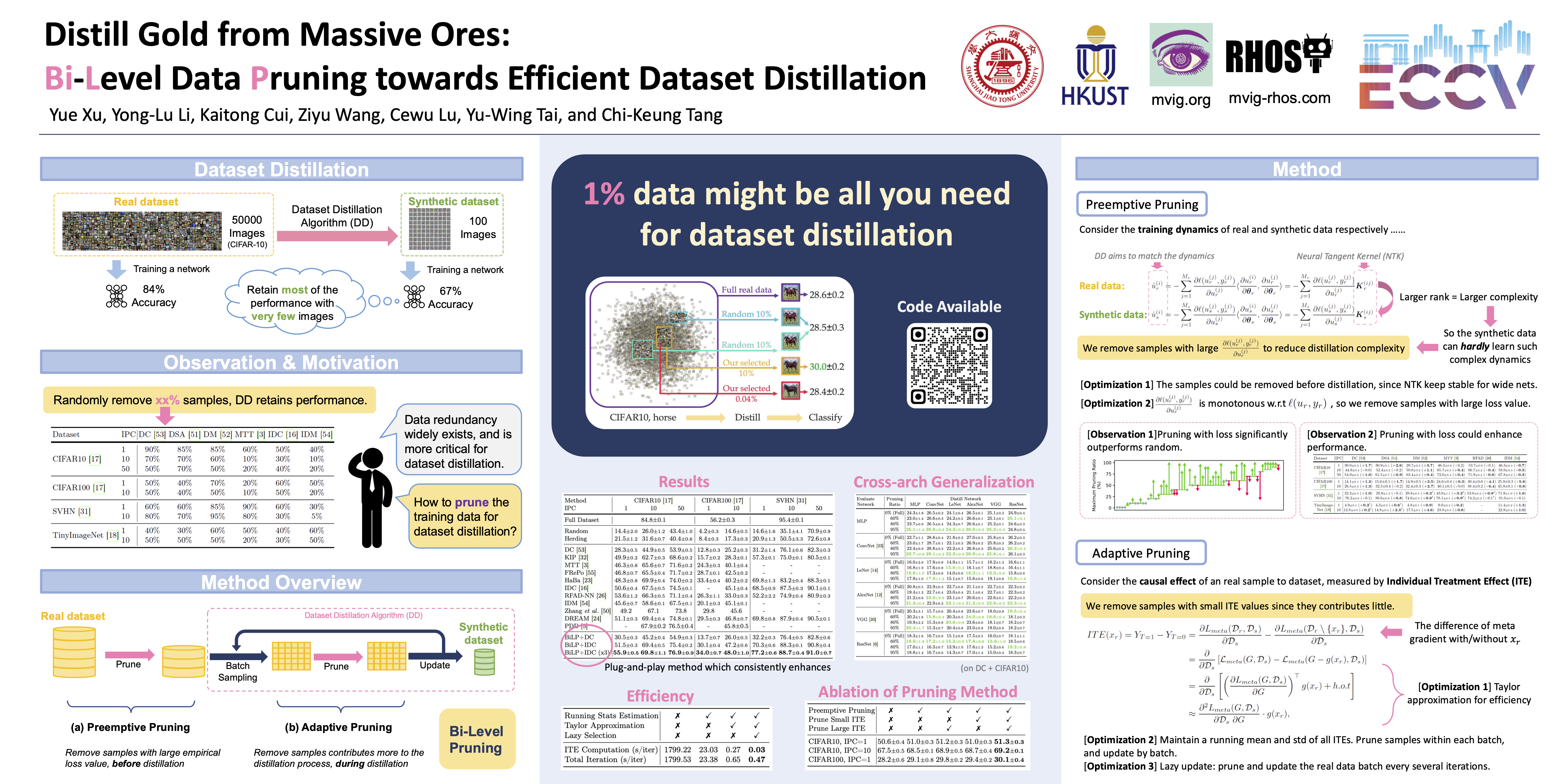
Data-efficient learning has garnered significant attention, especially given the current trend of large multi-modal models. Recently, dataset distillation has become an effective approach for data-efficiency by synthesizing data samples that are most essential for network training; however, it remains to be explored which samples are essential for the dataset distillation process itself. In this work, we study the data efficiency and selection for the dataset distillation task. By re-formulating the dynamics of distillation, we provide insight into the inherent redundancy in the real dataset, both theoretically and empirically. Thus we propose to use the empirical loss value as a static data pruning criterion. To further compensate for the variation of the data value in training, we propose to find the most contributing samples based on their causal effects on the distillation. The proposed selection strategy can efficiently exploit the training dataset and outperform the previous SOTA distillation algorithms, and consistently enhance the distillation algorithms, even on much larger-scale and more heterogeneous datasets, e.g. full ImageNet-1K and Kinetics-400. We believe this paradigm will open up new avenues in the dynamics of distillation and pave the way for efficient dataset distillation. Our code will be made publicly available.