Early Preparation Pays Off: New Classifier Pre-tuning for Class Incremental Semantic Segmentation
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
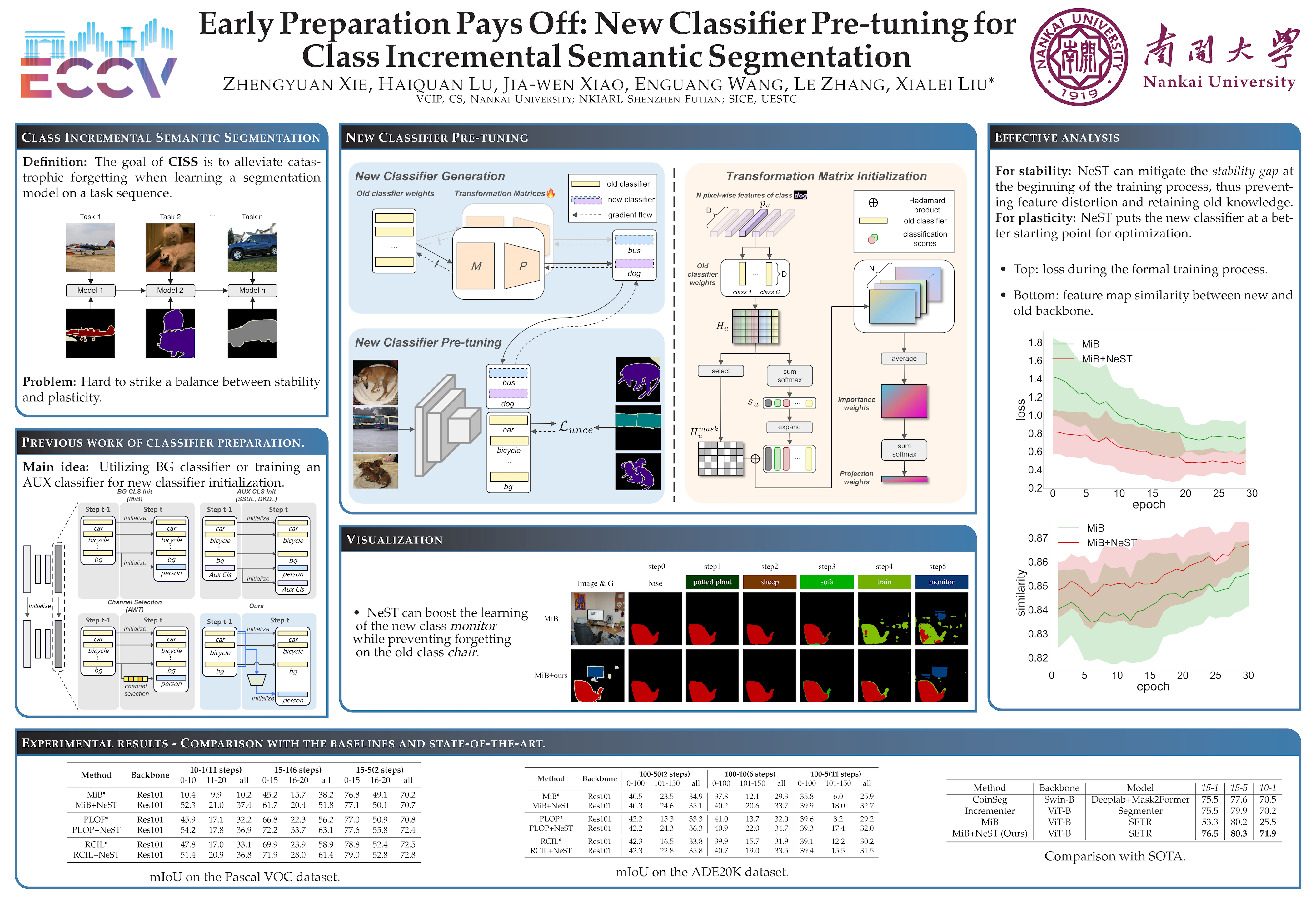
Class incremental semantic segmentation aims to preserve old knowledge while learning new tasks, however, impeded by catastrophic forgetting and background shift issues. Prior works indicate the pivotal importance of initializing new classifiers and mainly focus on transferring knowledge from the background classifier or preparing classifiers for future classes, neglecting the alignment and variance of new classifiers. In this paper, we propose a new classifier pre-tuning (NeST) method applied before the formal training process, learning a transformation from old classifiers to generate new classifiers for initialization rather than directly tuning the parameters of new classifiers. Our method can make new classifiers align with the backbone and adapt the new data, benefiting both the stability and plasticity of the model. Besides, we design a strategy considering the cross-task class similarity to initialize matrices used in the transformation. Experiments on Pascal VOC 2012 and ADE20K datasets show that the proposed strategy can significantly improve the performance of previous methods.