Characterizing Model Robustness via Natural Input Gradients
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
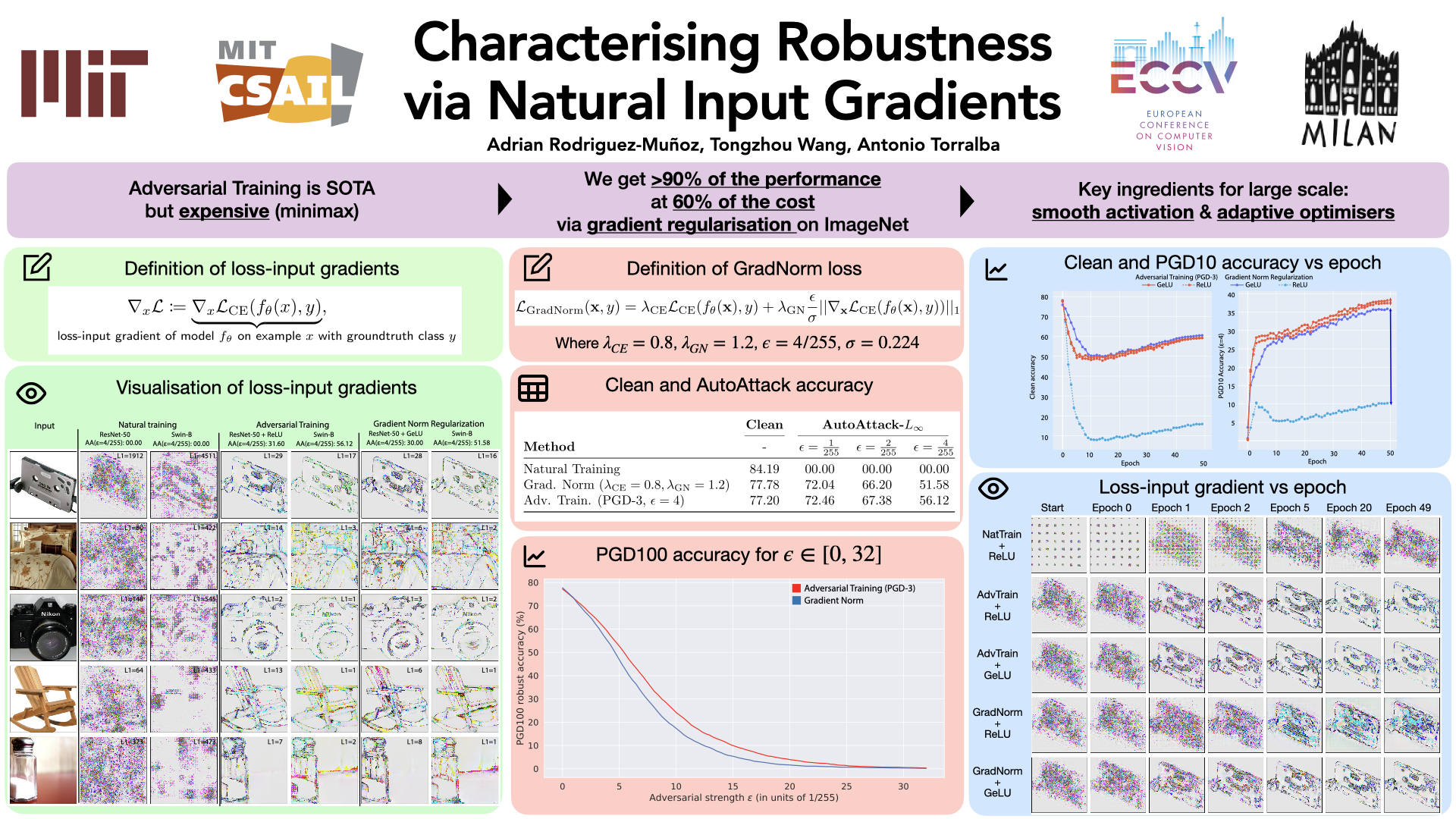
Adversarially robust models are locally smooth around each data sample so that small perturbations cannot drastically change model outputs. In modern systems, such smoothness is usually obtained via Adversarial Training, which explicitly enforces models to perform well on perturbed examples. In this work, we show the surprising effectiveness of instead regularizing the gradient with respect to model inputs on natural examples only. Penalizing input Gradient Norm is commonly believed to be a much inferior approach. Our analyses identify that the performance of Gradient Norm regularization critically depends on the smoothness of activation functions, and are in fact extremely effective on modern vision transformers that adopt smooth activations over piecewise linear ones (eg, ReLU). On ImageNet-1k, Gradient Norm training achieves > 90% performance of state-of-the-art PGD-3 Adversarial Training (52% vs. 56%), while using only 60% computation cost of the state-of-the-art without complex adversarial optimization. Our analyses further highlight the relationship between model robustness and properties of natural input gradients, such as asymmetric channel statistics. Surprisingly, we also find model robustness can be significantly improved by simply regularizing its gradients to focus on image edges without explicit conditioning on the norm.