Realistic Human Motion Generation with Cross-Diffusion Models
{kind=link}
Abstract
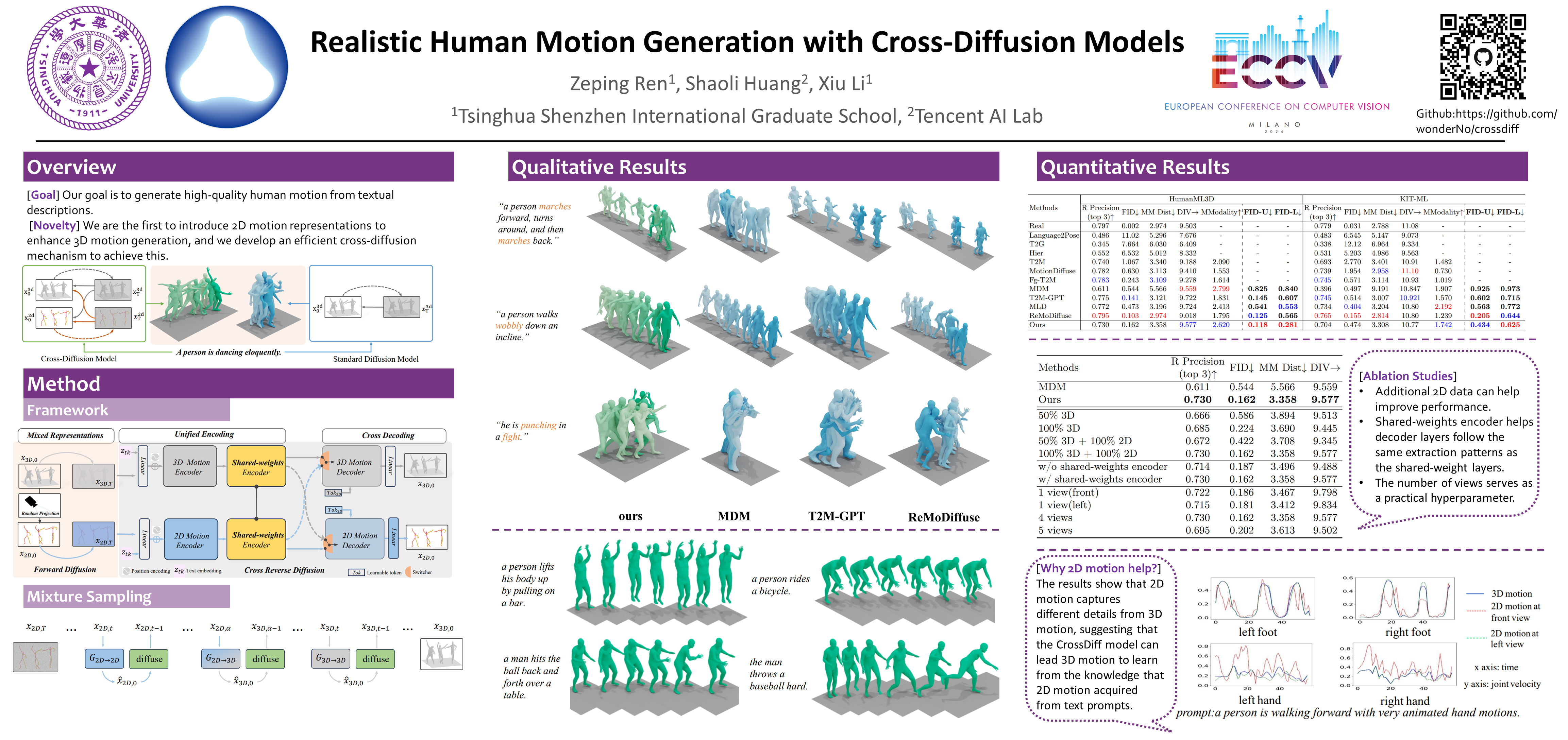
We introduce the Cross Human Motion Diffusion Model (CrossDiff), a novel approach for generating high-quality human motion based on textual descriptions. Our method integrates 3D and 2D information using a shared transformer network within the training of the diffusion model, unifying motion noise into a single feature space. This enables cross-decoding of features into both 3D and 2D motion representations, regardless of their original dimension. The primary advantage of CrossDiff is its cross-diffusion mechanism, which allows the model to reverse either 2D or 3D noise into clean motion during training. This capability leverages the complementary information in both motion representations, capturing intricate human movement details often missed by models relying solely on 3D information. Consequently, CrossDiff effectively combines the strengths of both representations to generate more realistic motion sequences. In our experiments, our model demonstrates competitive state-of-the-art performance on text-to-motion benchmarks. Moreover, our method consistently provides enhanced motion generation quality, capturing complex full-body movement intricacies. Additionally, with a pretrained model, our approach accommodates using in the wild 2D motion data without 3D motion ground truth during training to generate 3D motion, highlighting its potential for broader applications and efficient use of available data resources.