UNIC: Universal Classification Models via Multi-teacher Distillation
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
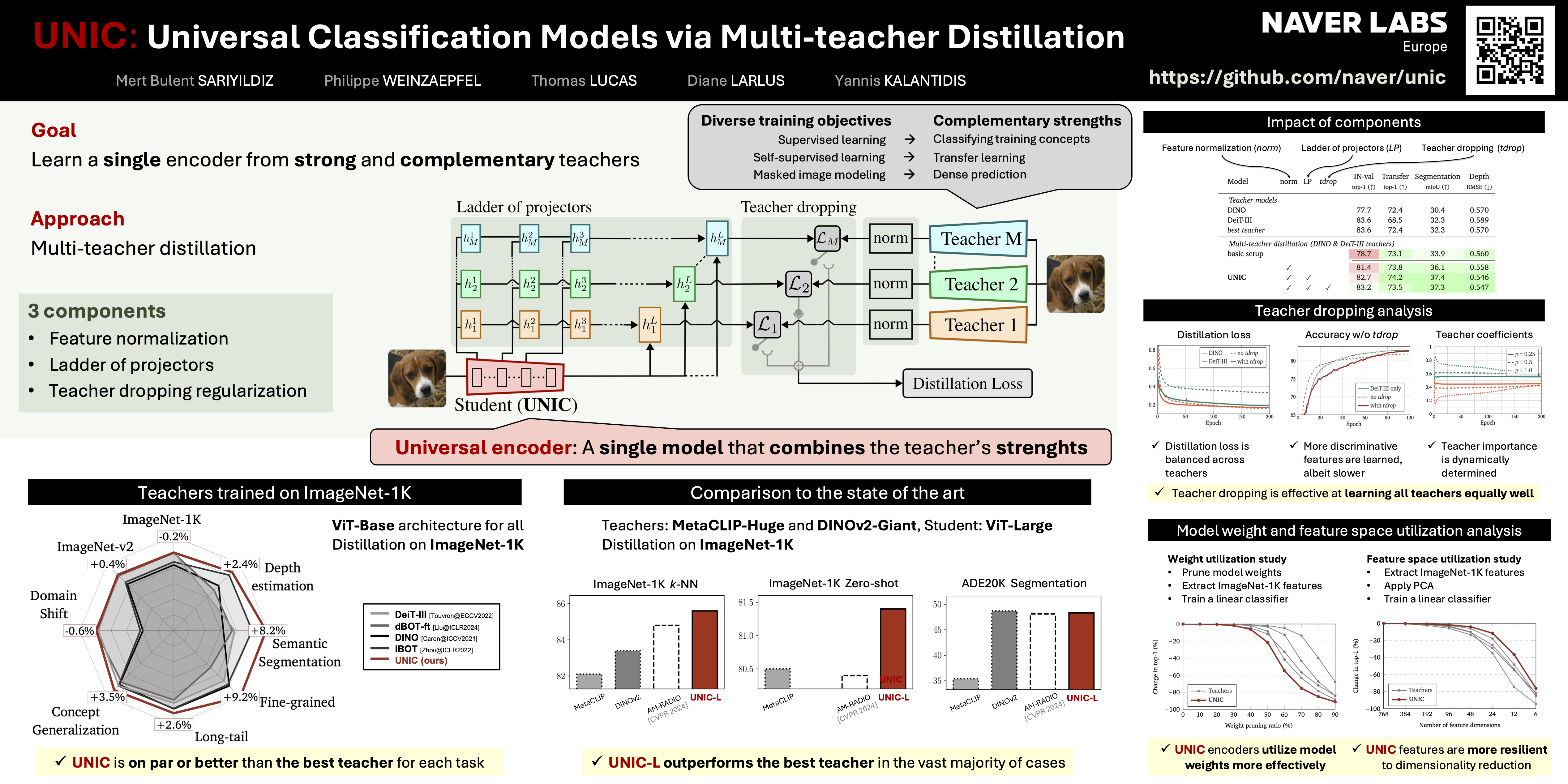
Pretrained models have become a commodity and offer strong results on a broad range of tasks. As they resort to different learning strategies, they tend to be complementary. In this work, we focus on classification and seek to learn a unique encoder able to take from several of those pretrained models. We aim at even stronger generalization across a variety of classification tasks. We propose to learn such an encoder via multi-teacher distillation. We first thoroughly analyse standard distillation when driven by multiple strong teachers with complementary strengths. Guided by this analysis, we gradually propose improvements to the basic distillation setup. Among those, we enrich the architecture of the encoder with a ladder of expendable projectors, which increases the impact of intermediate features during distillation, and we introduce teacher dropping, a regularization mechanism that better balances the teachers' influence. Our final distillation strategy leads to student models of the same capacity as any of the teachers, while retaining or improving upon the performance of the best teacher for each task.