Rotary Position Embedding for Vision Transformer
{kind=link}
Abstract
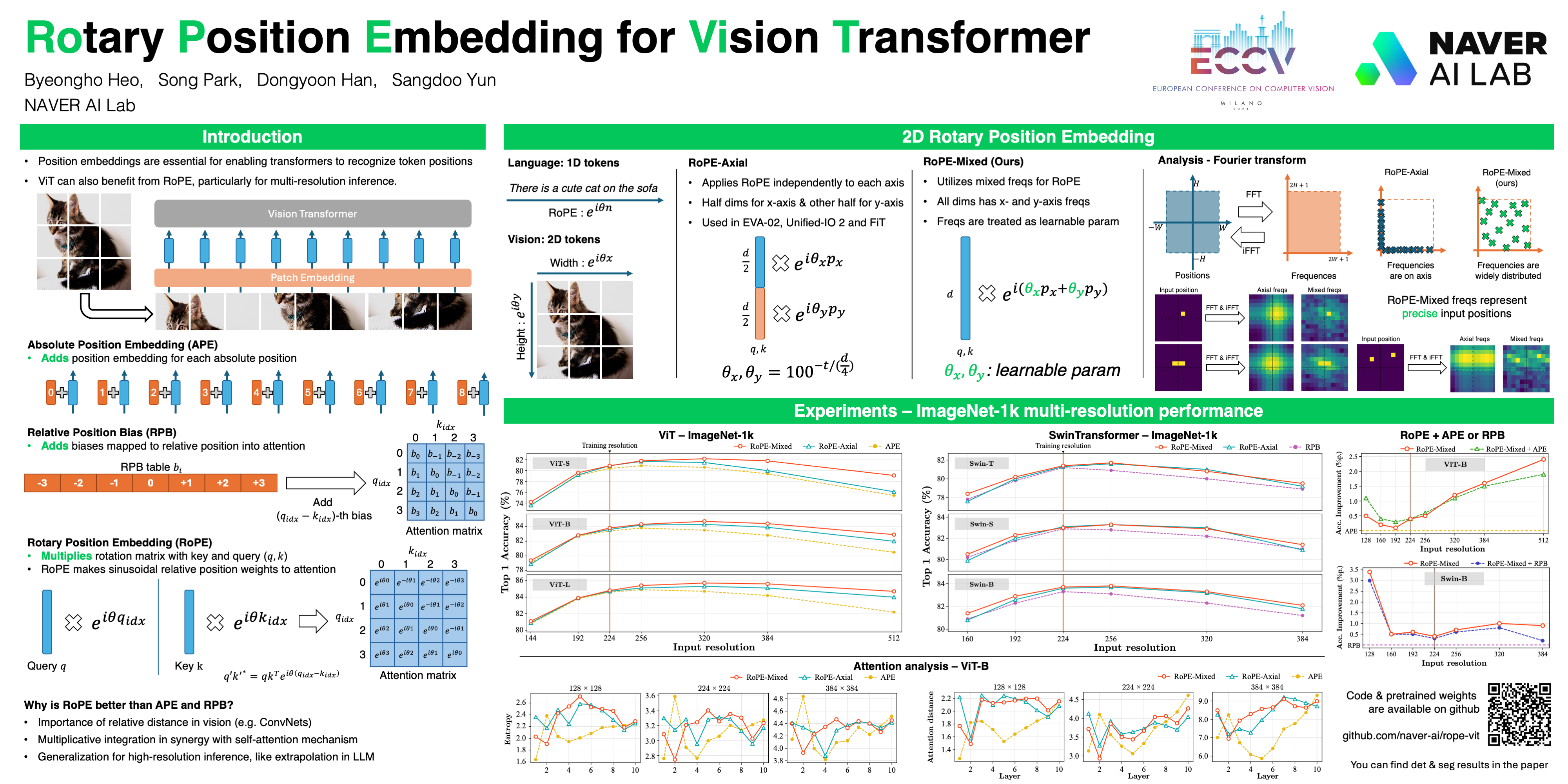
Rotary Position Embedding (RoPE) performs remarkably on language models, especially for length extrapolation of Transformers. However, the impacts of RoPE on computer vision domains have been underexplored, even though RoPE appears capable of enhancing Vision Transformer (ViT) performance in a way similar to the language domain. This study provides a comprehensive analysis of RoPE when applied to ViTs, utilizing practical implementations of RoPE for 2D vision data. The analysis reveals that RoPE demonstrates impressive extrapolation performance, i.e., maintaining precision while increasing image resolution at inference. It eventually leads to performance improvement for ImageNet-1k, COCO detection, and ADE-20k segmentation. We believe this study provides thorough guidelines to apply RoPE into ViT, promising improved backbone performance with minimal extra computational overhead. Our code and pre-trained models will be publicly released.