Human-in-the-Loop Visual Re-ID for Population Size Estimation
{kind=link}
Abstract
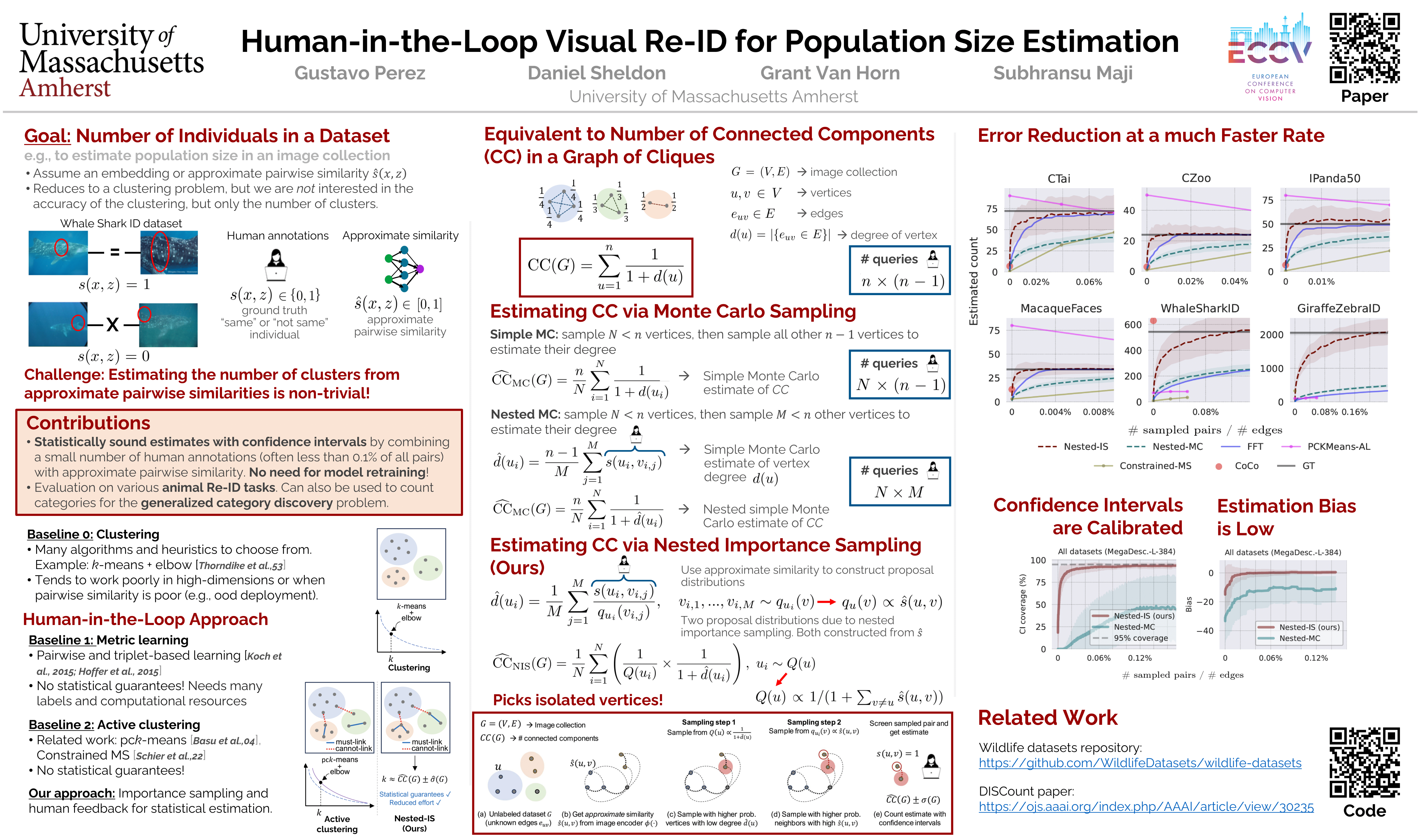
Computer vision-based re-identification (Re-ID) systems are increasingly being deployed for estimating population size in large image collections. However, the estimated size can be significantly inaccurate when the task is challenging or when deployed on data from new distributions. We propose a human-in-the-loop approach for estimating population size driven by a pairwise similarity derived from an off-the-shelf Re-ID system. Our approach, based on nested importance sampling, selects pairs of images for human vetting driven by the pairwise similarity, and produces asymptotically unbiased population size estimates with associated confidence intervals. We perform experiments on various animal Re-ID datasets and demonstrate that our method outperforms strong baselines and active clustering approaches. In many cases, we are able to reduce the error rates of the estimated size from around 80\% using CV alone to less than 20\% by vetting a fraction (often less than 0.002\%) of the total pairs. The cost of vetting reduces with the increase in accuracy and provides a practical approach for population size estimation within a desired tolerance when deploying Re-ID systems.