Pro2SAM: Mask Prompt to SAM with Grid Points for Weakly Supervised Object Localization
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
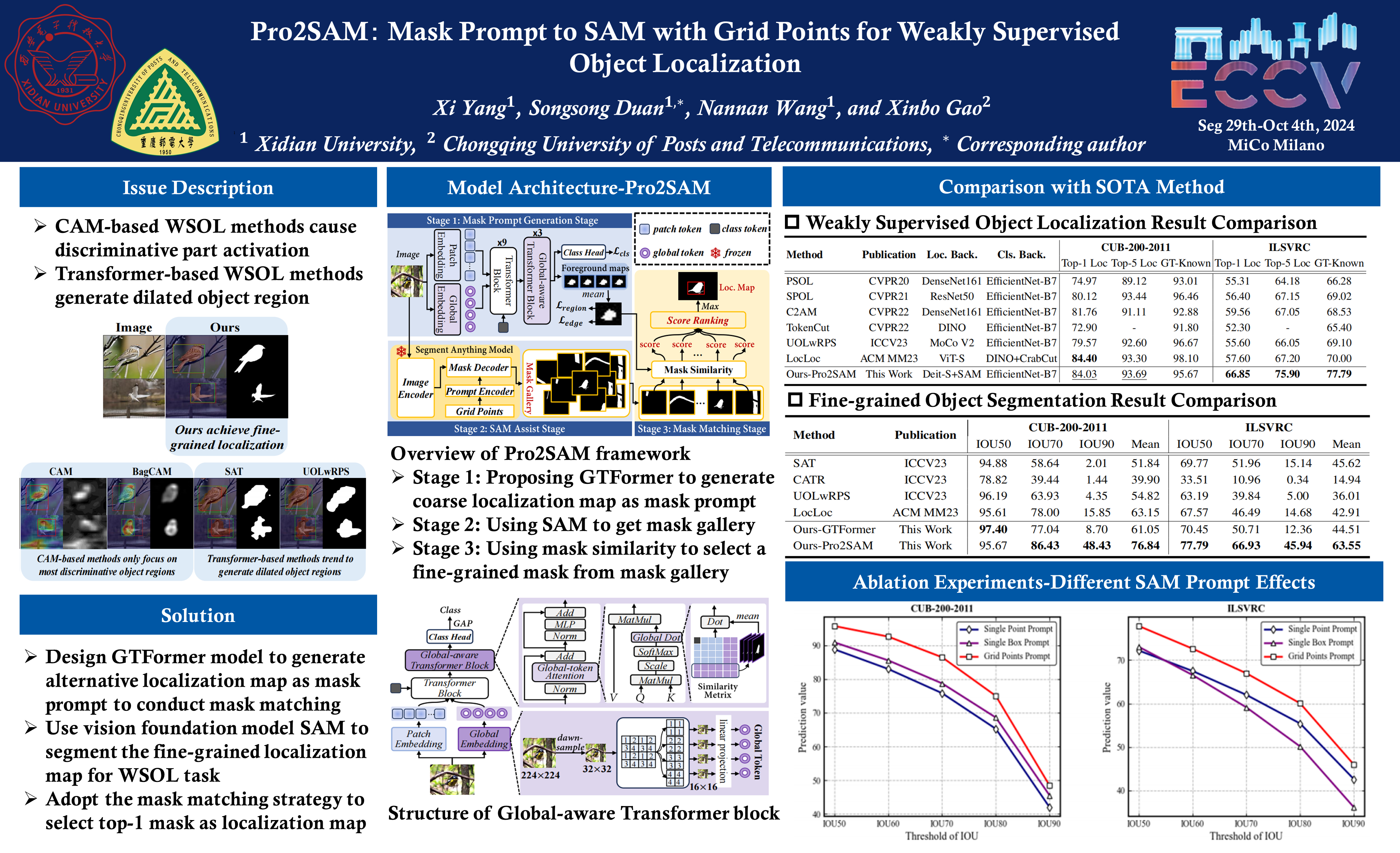
Weakly Supervised Object Localization (WSOL), which aims to localize objects by only using image-level labels, has attracted much attention because of its low annotation cost in real applications. Current studies focus on the Class Activation Map (CAM) of CNN and the self-attention map of transformer to identify the region of objects. However, both CAM and self-attention maps can not learn pixel-level fine-grained information on the foreground objects, which hinders the further advance of WSOL. To address this problem, we initiatively leverage the capability of zero-shot generalization and fine-grained segmentation in Segment Anything Model (SAM) to boost the activation of integral object regions. Further, to alleviate the semantic ambiguity issue accrued in single point prompt-based SAM, we propose an innovative mask prompt to SAM (Pro2SAM) network with grid points for WSOL task. First, we devise a Global Token Transformer (GTFormer) to generate a coarse-grained foreground map as a flexible mask prompt, where the GTFormer jointly embeds patch tokens and novel global tokens to learn foreground semantics. Secondly, we deliver grid points as dense prompts into SAM to maximize the probability of foreground mask, which avoids the lack of objects caused by a single point/box prompt. Finally, we propose a pixel-level similarity metric to come true the mask matching from mask prompt to SAM, where the mask with the highest score is viewed as the final localization map. Experiments show that the proposed Pro2SAM achieves state-of-the-art performance on both CUB-200-2011 and ILSVRC, with 84.03% and 66.85% Top-1 Loc, respectively.