Leveraging Text Localization for Scene Text Removal via Text-aware Masked Image Modeling
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
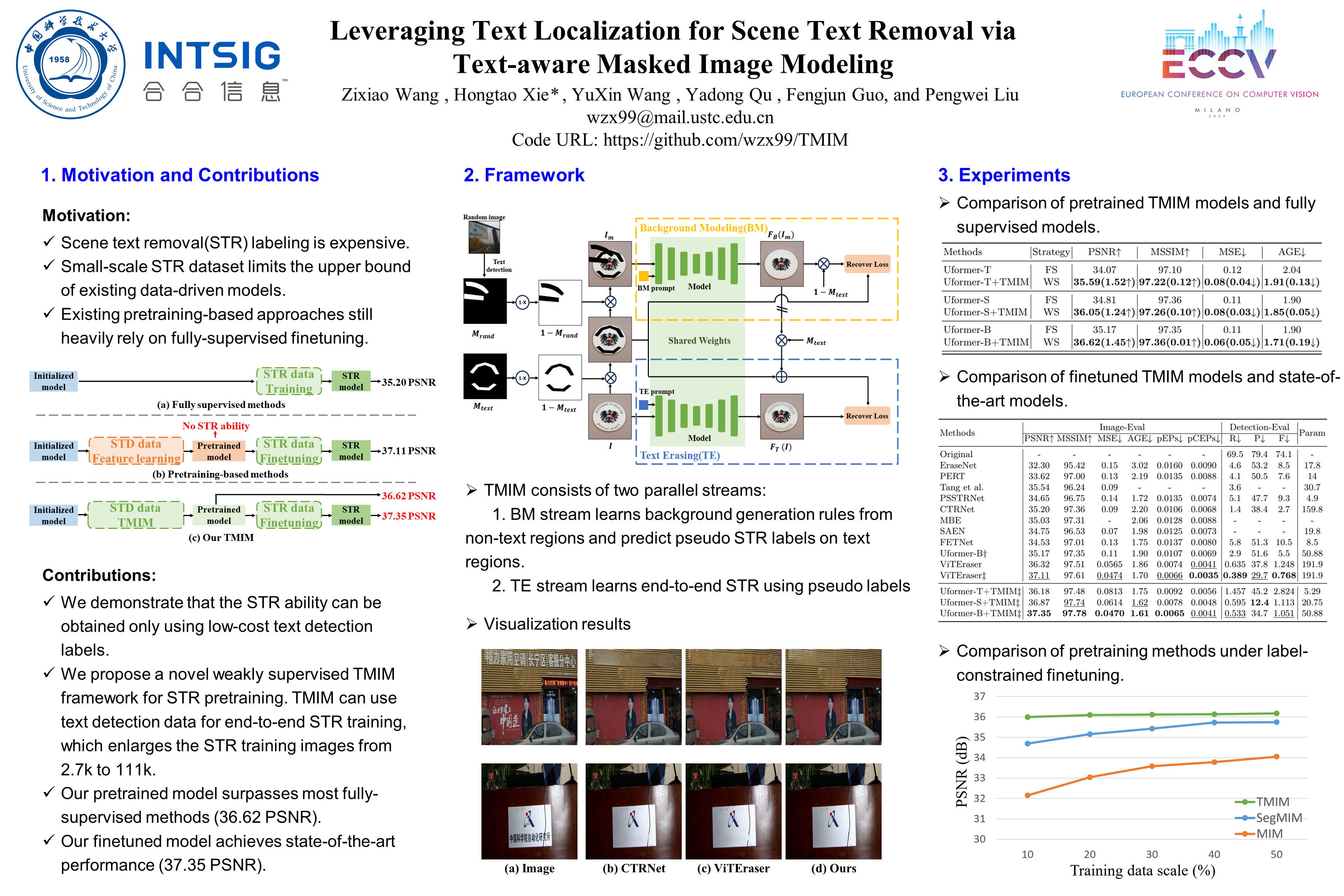
Existing scene text removal (STR) task suffers from insufficient training data due to the expensive pixel-level labeling. In this paper, we aim to address this issue by introducing a Text-aware Masked Image Modeling algorithm (TMIM), which can pretrain STR models with low-cost text detection labels (e.g., text bounding box). Different from previous pretraining methods that use indirect auxiliary tasks only to enhance the implicit feature extraction ability, our TMIM first enables the STR task to be directly trained in a weakly supervised manner, which explores the STR knowledge explicitly and efficiently. In TMIM, first, a Background Modeling stream is built to learn background generation rules by recovering the masked non-text region. Meanwhile, it provides pseudo STR labels on the masked text region. Second, a Text Erasing stream is proposed to learn from the pseudo labels and equip the model with end-to-end STR ability. Benefiting from the two collaborative streams, our STR model can achieve impressive performance only with the public text detection datasets, which greatly alleviates the limitation of the high-cost STR labels. Experiments demonstrate that our method outperforms other pretrain methods and achieves state-of-the-art performance (37.35 PSNR on SCUT-EnsText). Code will be available.