STSP: Spatial-Temporal Subspace Projection for Video Class-incremental Learning
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
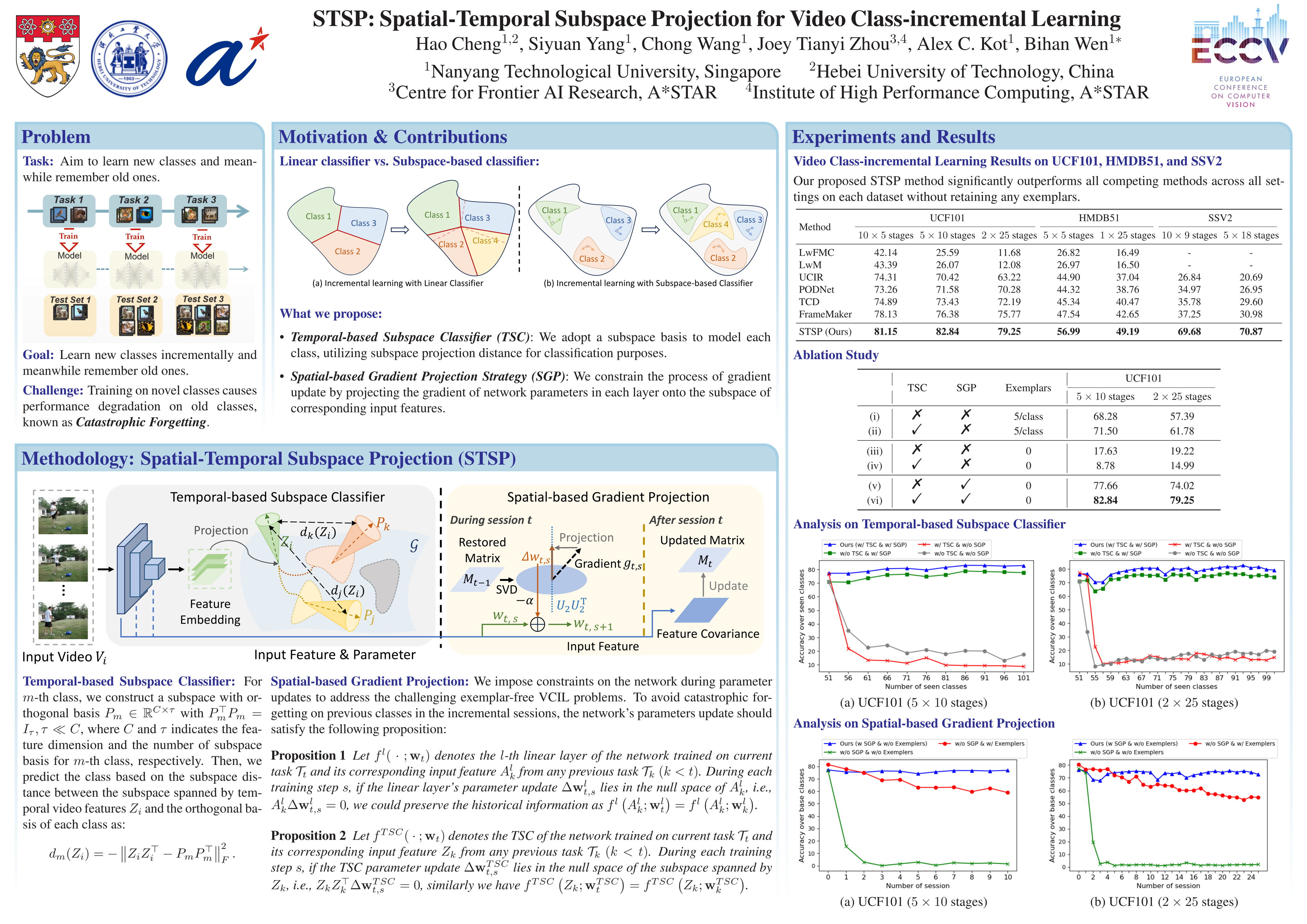
Video class-incremental learning (VCIL) aims to learn discriminative and generalized feature representations for video frames to mitigate catastrophic forgetting. Conventional VCIL approaches often retain a subset of frames or features from prior tasks as exemplars for subsequent incremental learning stages. However, these strategies overlook the connection between base and novel classes, sometimes even leading to privacy leakage. To overcome this challenge, we introduce a Spatial-Temporal Subspace Projection (STSP) scheme for VCIL. Specifically, we propose a discriminative Temporal-based Subspace Classifier (TSC) that represents each class with an orthogonal subspace basis and adopts subspace projection loss for classification. Differing from typical classification methods that rely on fully connected layers, our TSC is designed to discern the spatial-temporal dynamics in video content, thereby enhancing the representation of each video sample. Additionally, we implement inter- and intra-class orthogonal constraints into TSC, ensuring that each class occupies a unique orthogonal subspace, defined by its basis. To prevent catastrophic forgetting, we further employ a Spatial-based Gradient Projection (SGP) strategy. SGP adjusts the gradients of the network parameters to align with the approximate null space of the spatial feature set from previous tasks. Extensive experiments conducted on three benchmarks, namely HMDB51, UCF101, and Something-Something V2, demonstrate that our STSP method outperforms state-of-the-art comparison methods,