Hierarchical Unsupervised Relation Distillation for Source Free Domain Adaptation
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
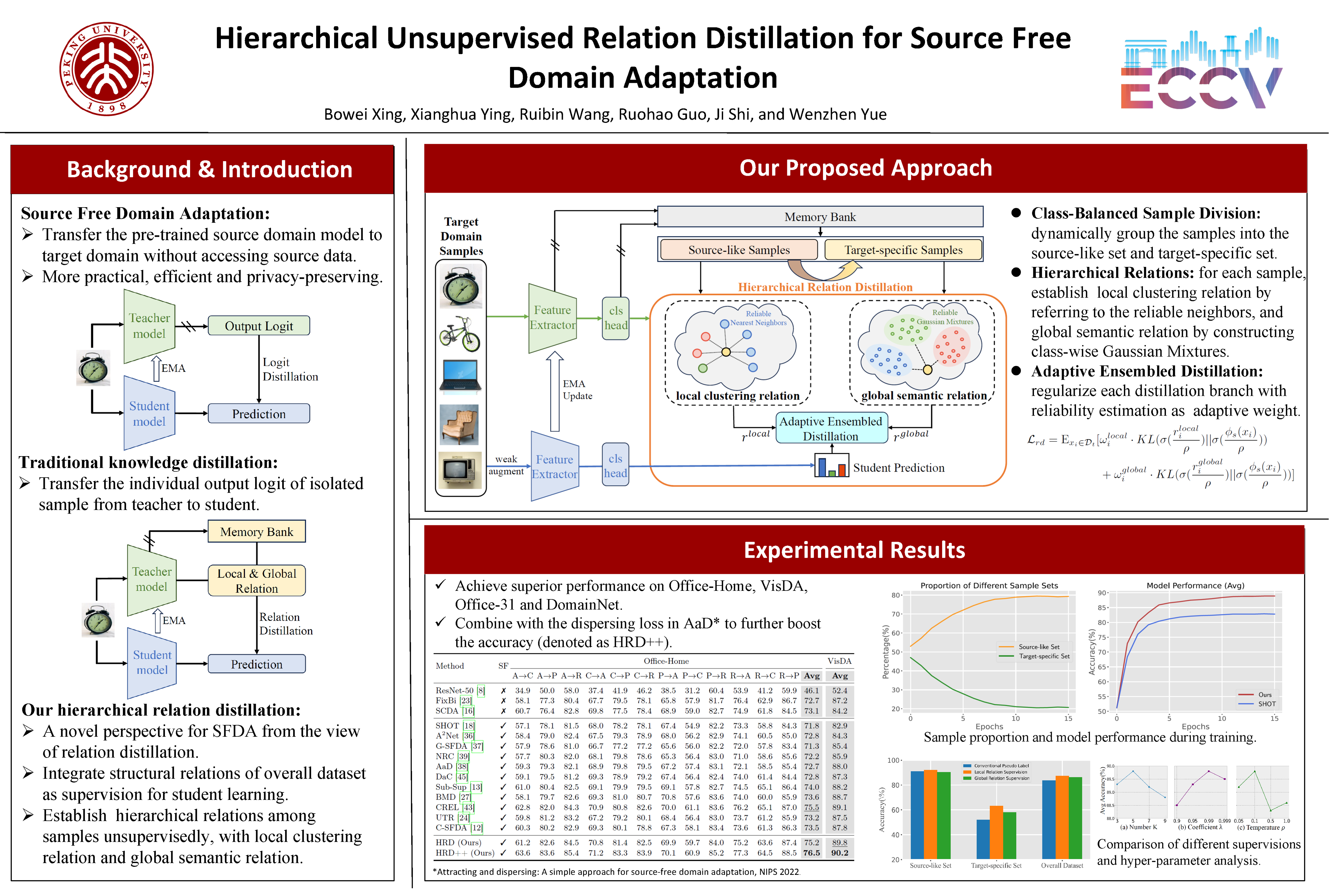
Source free domain adaptation (SFDA) aims to transfer the model trained on labeled source domain to unlabeled target domain without accessing source data. Recent SFDA methods predominantly rely on self-training, which supervise the model with pseudo labels generated from individual data samples. However, they often ignore the crucial data structure information and sample relationships that are beneficial for adaptive training. In this paper, we propose a novel hierarchical relation distillation framework, establishing multi-level relations across samples in an unsupervised manner, which fully exploits inherent data structure to guide the sample training instead of using the isolated pseudo labels. We first distinguish the source-like samples based on prediction reliability in the training process, followed by an effort on distilling knowledge to those target-specific ones by transferring both local clustering relation and global semantic relation. Specifically, we leverage the affinity with nearest neighborhood samples for local relation and consider the similarity to category-wise Gaussian Mixtures for global relation, offering complementary supervision to facilitate student learning. To validate the effectiveness of our approach, we conduct extensive experiments on four diverse benchmarks, achieving better performance compared to previous methods.