SHERL: Synthesizing High Accuracy and Efficient Memory for Resource-Limited Transfer Learning
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
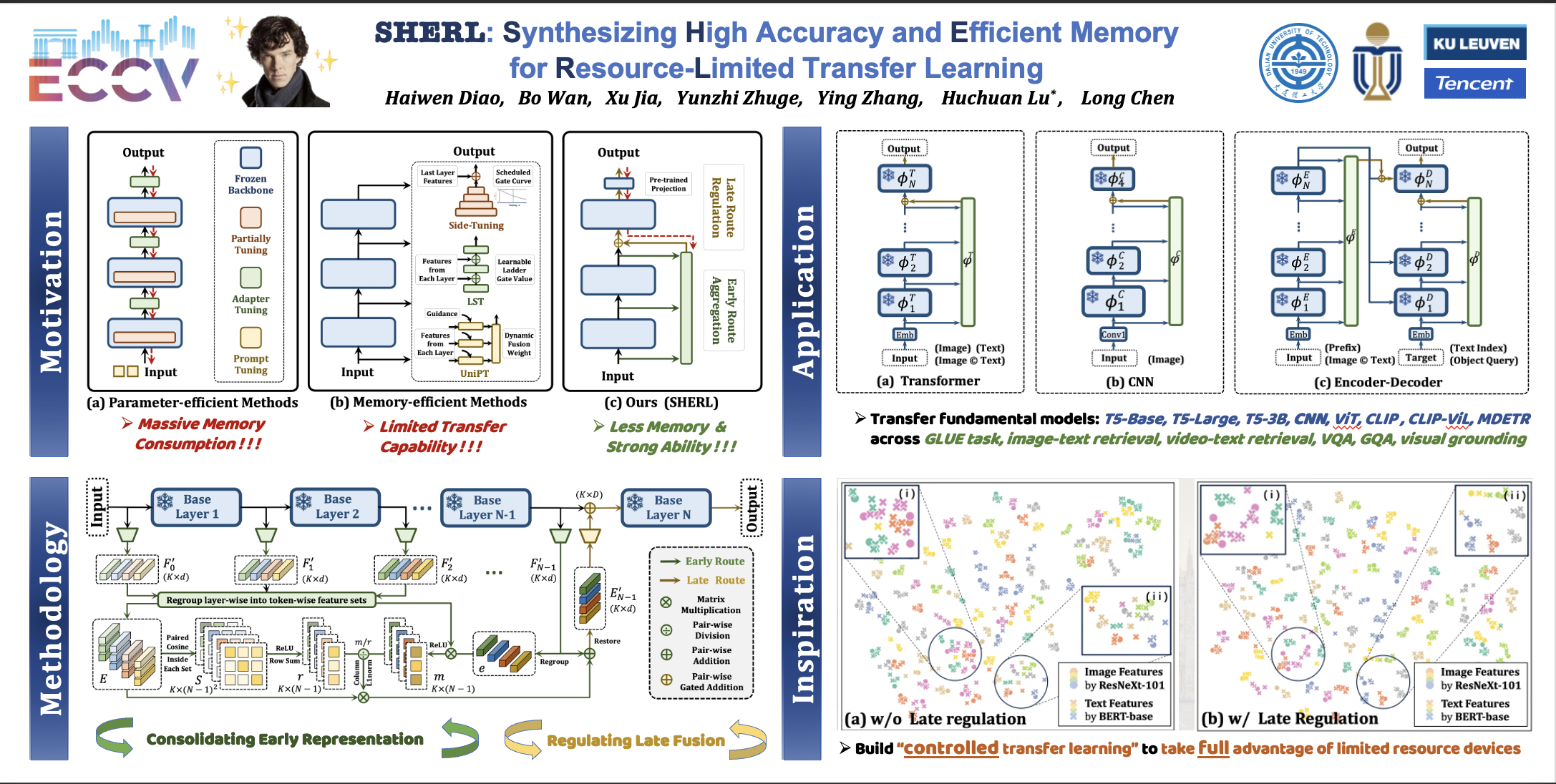
Parameter-efficient transfer learning (PETL) has emerged as a flourishing research field for its ability to adapt large pre-trained models to downstream tasks, greatly reducing trainable parameters while grappling with memory challenges during fine-tuning. To further alleviate memory burden, memory-efficient series (METL) avoid backpropagating gradients through the large backbone. However, they compromise by exclusively relying on frozen intermediate outputs and limiting the exhaustive exploration of prior knowledge from pre-trained models. Moreover, the dependency and redundancy between cross-layer features are frequently overlooked, thereby submerging more discriminative representations and causing an inherent performance gap (vs. conventional PETL methods). Hence, we propose an innovative strategy called SHERL, which stands for Synthesizing High-accuracy and Efficient-memory under Resource-Limited scenarios. Concretely, SHERL introduces a Multi-Tiered Sensing Adapter (MTSA) to decouple the entire adaptation into two successive and complementary processes. In the early route, intermediate outputs are consolidated via an anti-redundancy operation, enhancing their compatibility for subsequent interactions; thereby in the late route, utilizing minimal late pre-trained layers could alleviate the peak demand on memory overhead and regulate these fairly flexible features into more adaptive and powerful representations for new domains. We validate SHERL on 18 datasets across various vision-and-language and language-only NLP tasks. Extensive ablations demonstrate that SHERL combines the strengths of both parameter and memory-efficient techniques, performing on-par or better across diverse architectures with lower memory during fine-tuning.