SemiVL: Semi-Supervised Semantic Segmentation with Vision-Language Guidance
{kind=link}
Abstract
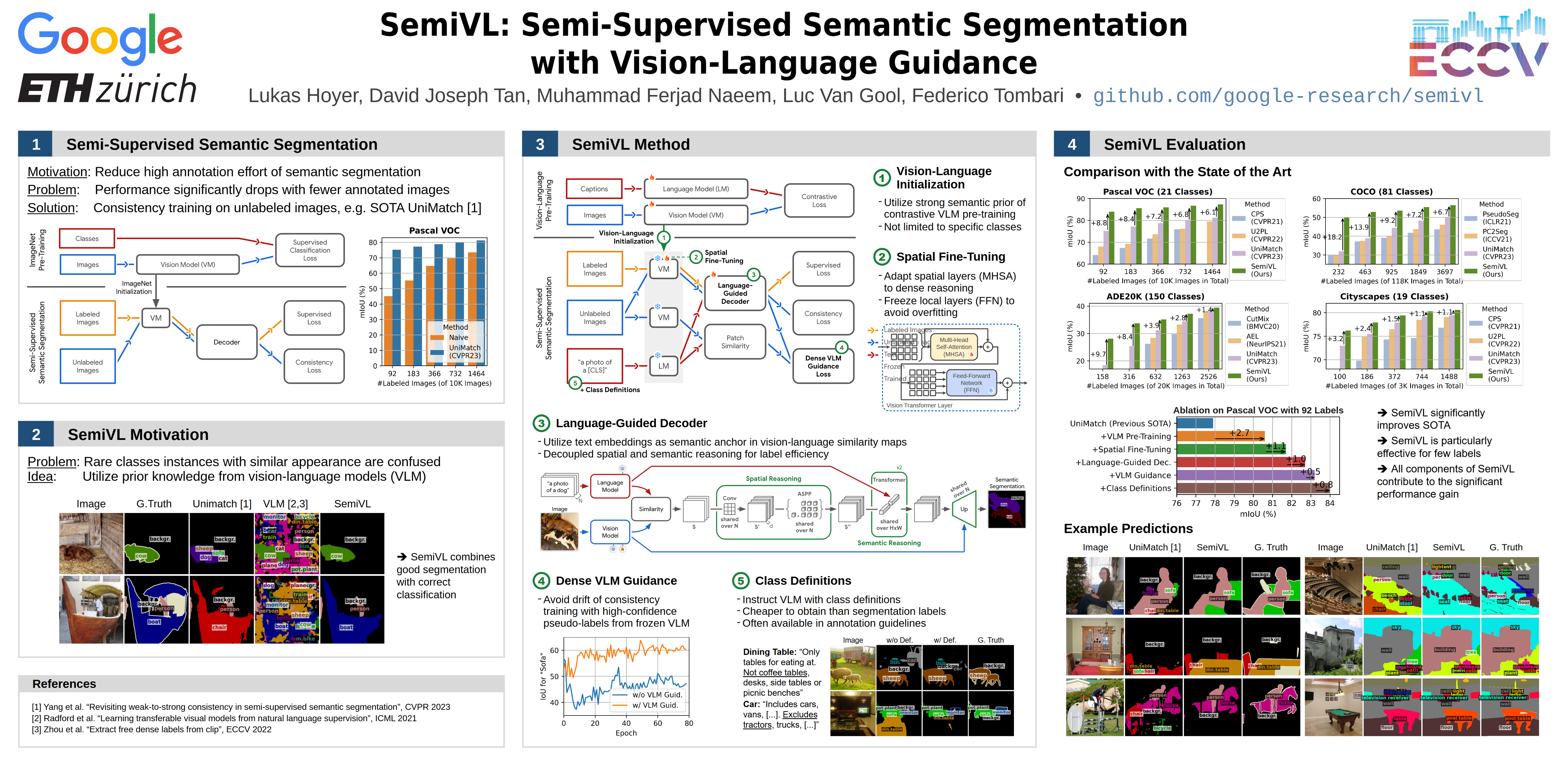
In semi-supervised semantic segmentation, a model is trained with a limited number of labeled images along with a large corpus of unlabeled images to reduce the high annotation effort. While previous methods are able to learn good segmentation boundaries, they are prone to confuse classes with similar visual appearance due to the limited supervision. On the other hand, vision-language models (VLMs) are able to learn diverse semantic knowledge from image-caption datasets but produce noisy segmentation due to the image-level training. In SemiVL, we newly propose to integrate rich priors from VLM pre-training into semi-supervised semantic segmentation to learn better semantic decision boundaries. To adapt the VLM from global to local reasoning, we introduce a spatial fine-tuning strategy for label-efficient learning. Further, we design a language-guided decoder to jointly reason over vision and language. Finally, we propose to handle inherent ambiguities in class labels by instructing the model with language guidance in the form of class definitions. We evaluate SemiVL on 4 semantic segmentation datasets, where it significantly outperforms previous semi-supervised methods. For instance, SemiVL improves the state of the art by +13.5 mIoU on COCO with 232 annotated images and by +6.1 mIoU on Pascal VOC with 92 annotated images. The source code will be released with the paper.