RealViformer: Investigating Attention for Real-World Video Super-Resolution
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
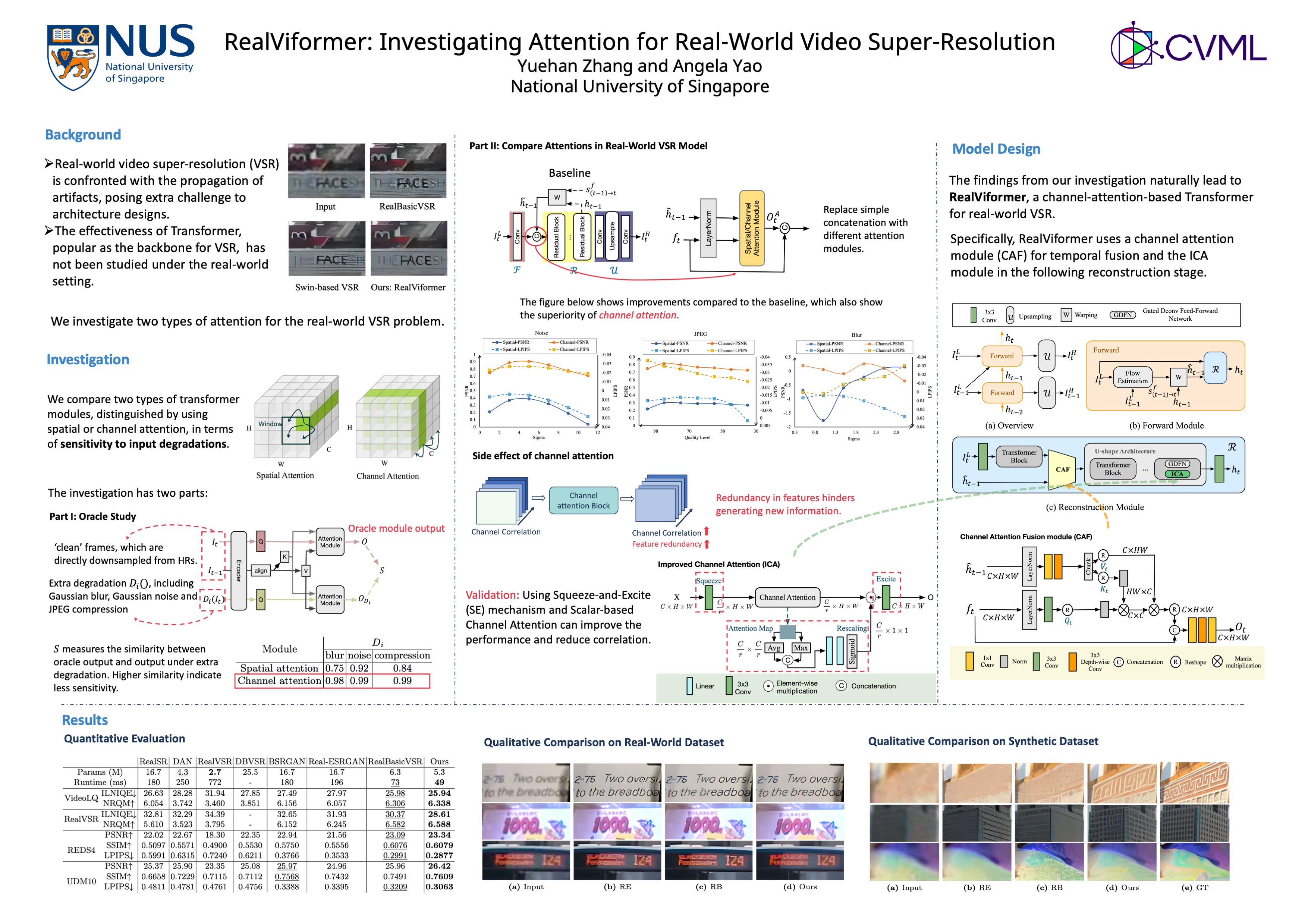
In real-world video super-resolution (VSR), videos suffer from in-the-wild degradations and artifacts. VSR methods, especially recurrent ones, tend to propagate artifacts over time in the real-world setting and are more vulnerable than image super-resolution. This paper investigates the influence of artifacts on commonly used covariance-based attention mechanisms in VSR. Comparing the widely-used spatial attention, which computes covariance over space, versus the less common channel attention, we observe that the latter is less sensitive to artifacts. However, channel attention leads to feature redundancy - evidenced by the higher covariance among output channels. As such, we explore simple techniques such as the squeeze-excite mechanism and covariance-based rescaling to counter the effects of high channel covariance. Based on our findings, we propose RealViformer. This channel-attention-based real-world VSR framework surpasses state-of-the-art on two real-world VSR datasets with fewer parameters and faster runtimes.