Unsupervised Variational Translator for Bridging Image Restoration and High-Level Vision Tasks
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
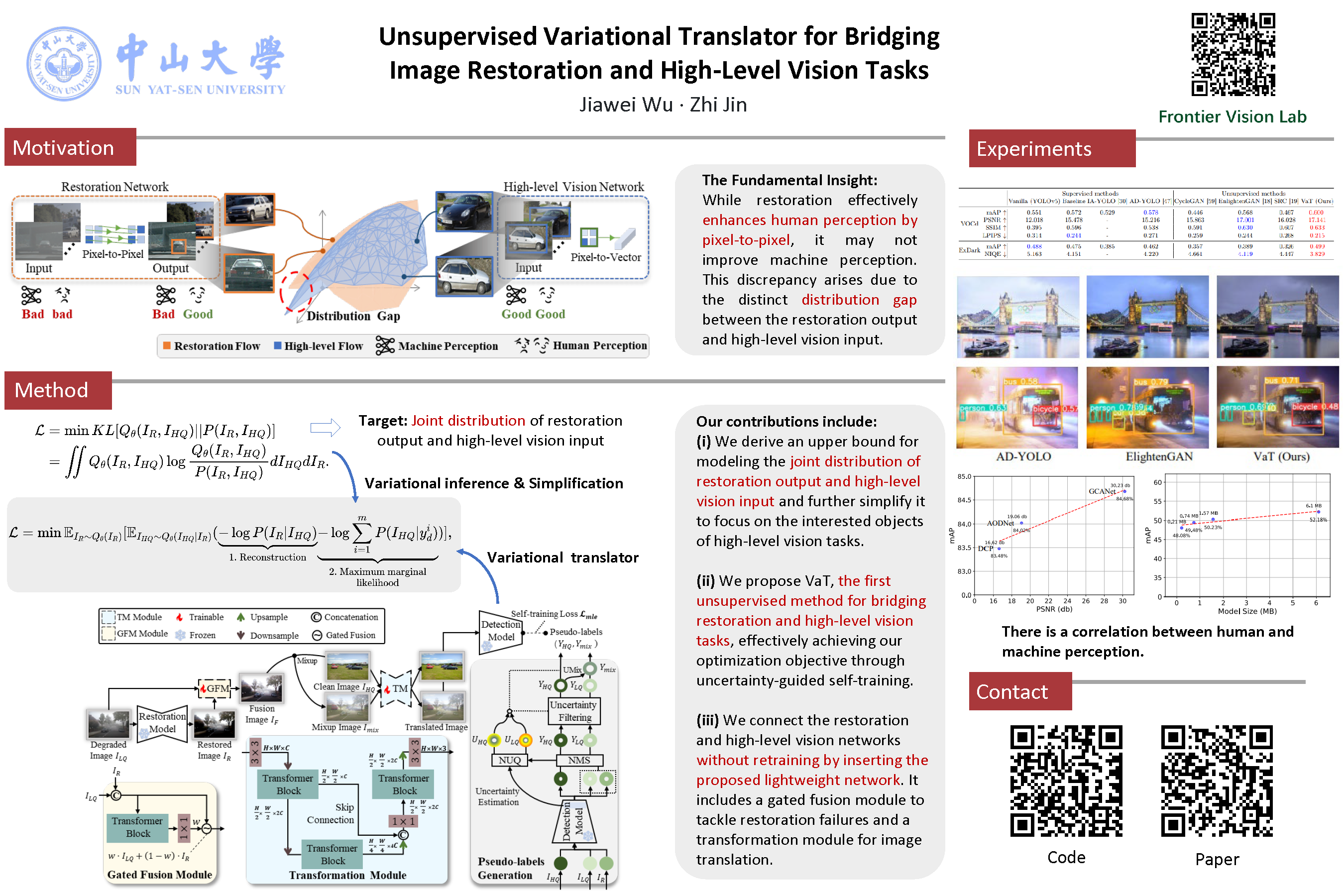
Recent research tries to extend image restoration capabilities from human perception to machine perception, thereby enhancing the performance of high-level vision tasks in degraded environments. These methods, primarily based on supervised learning, typically involve the retraining of restoration networks or high-level vision networks. However, collecting paired data in real-world scenarios poses a challenge, and with the increasing attention of large-scale models, retraining becomes an inefficient and cost-prohibitive solution. To this end, we propose an unsupervised learning method called Variational Translator (VaT), which does not require retraining existing restoration and high-level vision networks. Instead, it establishes a lightweight network that serves as an intermediate bridge between them. By variational inference, VaT approximates the joint distribution of restoration output and high-level vision input, dividing the optimization objective into preserving content and maximizing marginal likelihood associated with high-level vision tasks. By cleverly leveraging self-training paradigms, VaT achieves the above optimization objective without requiring labels. As a result, the translated images maintain a close resemblance to their original content while also demonstrating exceptional performance on high-level vision tasks. Extensive experiments in dehazing and low-light enhancement for detection and classification show the superiority of our method over other state-of-the-art unsupervised counterparts, even significantly surpassing supervised methods in some complex real-world scenarios.