MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
{kind=link}
Abstract
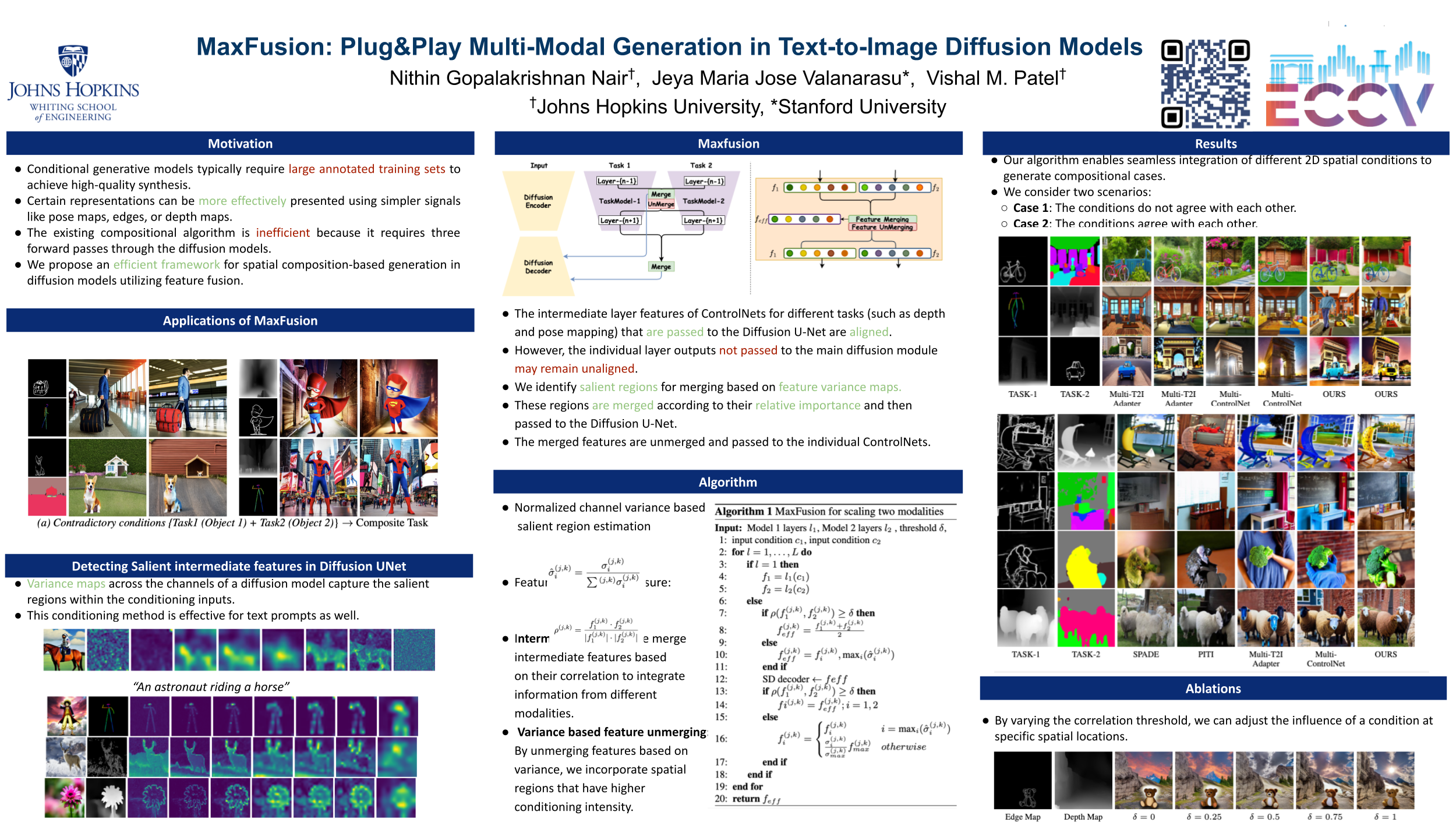
Large diffusion-based Text-to-Image (T2I) has shown impressive generative powers for text-to-image generation and spatially conditioned generation which makes the generated image follow the semantics of the condition. For most applications, we can train the model end-to-end with paired data to obtain photorealistic generation quality. However to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retrain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models. Specifically, we combine aligned features of multiple models hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess. We show the effectiveness of our method by utilizing off-the-shelf models for multi-modal generation to show the effectiveness of our method. To facilitate further research, we will make the code public.